中文语言服务(language server)的畅想和基础实现
前记
这周 emacs 升级到了 28, 于是想体验一下 lsp-bridge, 我对编程语言的 lsp 兴趣不大,例如日常用的 python 环境是 elpy + company, 功能齐全且稳定,静态的 jedi 补全速度很快,tag 解析也准,没有切换到 lsp 的欲望。但我对自然语言的 lsp 还是很感兴趣的,也就是中文的 language server.
准确来说,吸引我的是"语言服务" 这个名字,而不是内容,因为在真正开始实现之前我都还不知道 languageServerProtocol 具体是什么,只知道他会解析代码后返回比如高亮跳转等信息。
我更多是直觉上认为,怎么能给一个解析编程语言的通信协议取这么"抽象"的高大上的名字? 至少得叫做 programming language server protocol 吧?否则把中文英文等全世界几千种语言置于何地? 更别说几十万种动物语,或者三体人的语言了。 就好比你是学编程语言(PL)方向的学生,但简历上写自己是研究语言学的,虽然逻辑上没问题但似乎不着调。
当然我更倾向于认为,协议制定者是想先从取名字上就占据制高点,当前只满足编程语言,以后谁想做点自然语言的解析也可以放到这个协议的框架里来。这不,我就来吃螃蟹了,并且我也仿造这思路写下本文,:)。
language server protocol
本节我想用类比的方式来介绍一下什么是语言服务协议(LSP, language server protocol),因为具体的方式我也不会,要弄清还得看官方文档: Official page for Language Server Protocol
首先"协议" 一词本身就体现了需要两个以上的对象来达成某种共识,因此或许大部分协议都可以看作是 "通信协议", 而通信协议大体就是对一些附加信息的说明。
比如减肥的承诺可以看作一种协议,你为自己定下目标,要求三月后要减少 10 斤,这类承诺看似只有一个对象参与,但其实是当前的自己和未来自己的协议,如果你没有按照自己的承诺减肥(减肥这件事本身就是在实现协议),三个月后没有看到减少 10 斤的自己,那么和过去自己的这部分单向通信就失败了,你会抛出懊恼的"异常"。
以上例子可能也有点不着调了,还是回到最常见的例子 – 寄快递,如果想要给某人寄快递,需要遵循所在地区和快递公司的邮寄规范,例如寄信人和收件人格式怎么写等等,邮寄协议就是对这些规范的说明。
语言服务器(language server)是为了给软件开发提供智能辅助信息的,比如代码高亮,自动补全,根据变量找到变量定义。然而人们对 "智能" 的定义和认知一直是在演变的,这些所谓的智能都是一时的, 早期能把语言里的关键词和变量用特殊颜色凸显出来或许就算是智能了,但现在的智能也许是要让机器自动帮忙写代码,甚至取代自己,这听上去有种悲情的浪漫。
总之为了减轻理解上的负担,完全可以屏蔽所有细节,只把语言服务器看作是一个智能体,甚至是超级智能体,你在写代码的时候,这个智能体在一旁辅助,类似结队编程的队友或同事,区别在于程序员不是和语言服务器直接聊天沟通,两者之间还有一个第三者 – 编辑器。
我们把代码写到编辑器里, 编辑器根据 lsp 协议把代码信息装在合适的信封里传给语言服务器,语言服务器根据协议解开信封, 查看内容,然后心领神会,它知道了每个函数的具体实现和定义在项目的哪个文件哪一行(symbol definition/reference),接口文档(document),哪一行有语法错误(diagnostics), 程序员接下来最有可能输入哪些字符(补全,completion),它把这些信息又根据 lsp 协议装在不同的信封里打包返回给编辑器,编辑器解开第一个信封,看到 23 行第 3 个字符有语法错误,于是把这个位置高亮起来,解开另一个信封,看到一串推荐的字符串,于是弹出自动补全列表供你选择,打开最后一个信封,赫然写着“有内鬼,中止交易”,于是自动断开与语言服务器的连接 …
锵锵三人行
如果第三者是一般的 IDE 代码编辑器,例如 vscode, vim,可能我不会想到 "有内鬼" 的梗,因为大部分情况都是在编程环境下中规中矩地获得特定语言服务返回的信息。
但当它是 emacs 时, 事情开始变得有趣了,因为当前场景就变成了 语言服务 , emacs 和 坐在屏幕前的你 这三个智能体的交互了,产生的剧情或许足够写一部新的《三体》系列。
原因在于,LSP 只规定了传输信息的包装格式,至于在什么场景通信,传递什么信息,如何解释信息完全是自己安排, 比如在补全信息里返回一堆无意义的随机字符串甚至二进制图片序列。
另一方面,LSP 提供了许多对通用的编辑中哪些活动可以智能化的启发,现在让你想一下,对于写小说这个活动, 有哪些步骤可以自动化?可能想到的有推荐词汇,某些表达的替换等,但如果去看一看 lsp 协议,很快就会有更多的联想和类比,比如有 linkedEditingRange 这种修改文档里变量的请求,放在自然语言里就是类似找共指的问题?
想象这样一个场景,一位小说创作者写了 10 万字时,想要把主角张三的名字改成李四,还要把性别从男改成女(世界之大无奇不有),那么难道要肉眼把每个 "张三"改成"李四"吗? 当然不需要, Word 的 replace 功能就可以满足,但 10 万字小说里可不单只有"张三"才代表主角,还有他的各类昵称, 比如"小张","阿三"(也许还有"小三", 但 当前的"小三"指的是张三还是张三的小三?,另外"阿三"是真正的张三还是张三的印度朋友的外号?),更头疼的是,还有"他"这样的代词,需要转成“她”,因此如果能够把光标放在”张三”这个 symbol 上, 执行 linked editing 命令,编辑器弹出指向"张三" 的所有名称,昵称和代词供作者替换,至少把范围从 10 万字 narrow 成一个选择清单,小说 refactor 自动辅助加持,这位奇怪的作者岂不是有福了?
总之,我的个人感觉是 LSP 里每一条协议应该算是从万千程序员编程实践里提炼总结出来的东西,它对"代码编辑"这个活动做了比较系统的总结和规范。让你知道在编程活动中哪些东西应该由机器来计算,而不是由开发者。这可以给一般的编辑、作笔记活动提供启发。
而 emacs 的灵活性使得几乎可以用它做"任何事情",因此就可以(很保守地)想象以下场景:
语言服务在检测到写的代码没有那么"优雅" 时,可以给 emacs 发条消息播放一首音乐让你放松放松。
lsp-bridge 把补全前端(acm)和与 lsp 后端通信的框架都一起实现了,另外 wiki 和论坛里的讨论也很详细,这意味着在前端到后端路径上出现任何问题可以马上找到方法解决,应该不会有太多的卡顿。
因此当前万事俱备,就差一个 languge server 了,从想象上,前景是光明的😄。
中文语言服务
再畅想一刻钟
以下是我想到的中文或汉语的语言服务可以提供的主要功能:
输入拼音后自动补全汉语 这样可以基于上下文做预测,而不是纯粹根据局部的使用频率来排序, 另外也可以感受用补全来输入中文是什么体验,好处是不需要考虑切换输入法的问题。
这部分直接对应 lsp 中补全的协议部分,前端接口是 lsp-bridge-popup-complete
- 提供类似 emacs libpinyin 的功能,能够根据 pinyin 搜索和跳转,因为如果要实现拼音输入法, lsp 服务肯定要有中文到 pinyin 的映射表,也许可以通过 lsp-bridge-find-impl 来提供接口
- 分词功能: 中文里识别出 symbol 并不那么直接,需要分词,分词后可以提供局部词汇高亮的功能,这样用 M-f,M-b 进行词级别的移动或删除就很清晰了,比如可以用 lsp-bridge-return-from-def 接口返回词的边界位置信息。
- 中文的错别字高亮和纠正: lsp-bridge-list-diagnostics
- 中英文翻译: lsp-bridge-lookup-documentation 当然 document 接口还可以显示很多别的信息
- 以上都是局部的解析, lsp 有对处理大型编程项目的接口,对应中文来说, 最直接的例子就是对 org-roam 知识库做文档级别的解析,从算一算 page rank 到复杂的跨文档理解以及对可视化的支持等实际都或多或少可以找到相似的接口。 比如在编程项目里进行 symbol 的 reference 查询,可以对应到某个概念做语义上相似度的匹配和跳转。这部分更复杂了,先不想那么多。
以上除了第二个,每一项基本对应一个或多个研究课题,当然现成的解决方案也都是有的,但没有统一起来
拼音补全基本实现
本节介绍如何用 pygls 快速实现一个 lsp 服务,并且加入最基本的拼音补全功能,这件事情总体上看比较复杂, 又实现 lsp 服务又得实现输入法,但我当前的目的只是想把 emacs 到中文服务的通信搭建起来,而不是去实现一个 tabnine 类型的中文自动补全,因此找现有的拼音输入方案即可,甚至不需要输入法,直接写一个拼音到中文的查找表, 做一个 mock 测试就行,因此实际最终要写的代码不到 30 行(我也只看了补全这一功能的写法,其他都没实现)。
lsp 服务仅仅是一个命令行
首先 lsp 服务器只是一个命令行,执行这个命令行后,服务就开始守株待兔了,基本模型如下
while 1:
if emacs/editor send message to me:
read the message
do something fancy and reply to emacs
pygls 的封装
pygls 把整个服务都封装好了,因此基本的服务运行代码比以上伪代码还简单
首先 pip install pygls pypinyin; pypinyin 提供的是汉字到拼音的转换
from pygls.server import LanguageServer
LanguageServer().start_io()
如果这个脚本叫做 server.py, 那么执行 python server.py 就启动了一个等待服务, 但因为没有对消息的处理机制,此时它对收到的的任何消息的态度都是:不要回答。
收到 hello world 请回答
以下加入对编辑器发来的补全请求的回应
from pygls.capabilities import COMPLETION
from pygls.lsp import CompletionItem, CompletionList, CompletionParams
from pygls.server import LanguageServer
server = LanguageServer()
@server.feature(COMPLETION)
def completions(params: CompletionParams):
"""Returns completion items."""
return CompletionList(
is_incomplete=False,
items=[
CompletionItem(label='hello'),
CompletionItem(label='world'),
])
server.start_io()
实际这里只引入了 5 行新代码,看上去更多主要是因为 return 写了很多行。
关键就是用 @server.feature(COMPLETION) 对一个函数进行了装饰,函数当前取名为 completions, 但实际任何名字都行,装饰器把 completions 函数注册到了 lsp 服务中,它负责返回补全信息, 这些信息
要用 CompletionItem 和 CompletionList 包装起来( 和寄快递需要特定的包装一样)。
这样,如果从 lsp-bridge 端正常启动了这个服务,输入 hello 的任何前缀 (h,he,hel,hell)都会返回 hello 补全候选词。 同样,输入 world 的任何前缀都会返回 world 作为补全。
以上就是 LSP 服务的补全 hello world 程序了。
加入 demo 输入法
from pygls.capabilities import COMPLETION
from pygls.lsp import CompletionItem, CompletionList, CompletionParams
from pygls.server import LanguageServer
from pygls.lsp.types import Range, TextEdit
server = LanguageServer()
@server.feature(COMPLETION)
def completions(params: CompletionParams):
prefix = get_current_prefix(params)
cands = shurufa(prefix)
pos = get_current_cursor_pos(params)
items = []
for cand in cands:
text = TextEdit(range=Range(start=pos, end=pos), new_text=cand)
item = CompletionItem(label=prefix)
item.text_edit=text
items.append(item)
return CompletionList(is_incomplete=False, items=items)
server.start_io()
这里基本逻辑就是,从 params 参数里获得 emacs (或任何其他有 LSP 前端的编辑器)中光标前的前缀字符串,例如 nihao,输入法根据前缀 返回一个候选词列表,然后把这些候选词按协议规定包装好返回,中文候选词放在 TextEdit 段中,Range 表示插入词的替换范围(默认 start 和 end 都用 params 中默认传过来的当前光标所在位置), 以上程序中所有包含大写字母的变量都可以在 LSP 服务官方说明里找到对应的协议接口。
以下是一个用于测试的输入法实现,在这个输入法下,输入 nihao 候选菜单中会出现两个中文选项
def shurufa(prefix):
if prefix == "haihao":
return ["你好", "逆号"]
return []
输入 nihao 后发生什么?
emacs 中有任何输入变化,lsp-bridge 都会把消息发给 LSP 服务,但只有输入 nihao 以后,LSP 服务才返回了真正有用的消息。之后 lsp-bridge 目录下的 core/handler/completion.py 中的 process_response(self, response: dict) 得到的第一个 item 信息如下:
[{'key': '0,nihao', 'icon': '', 'label': 'nihao', 'deprecated': False, 'insertText': None, 'insertTextFormat': '', 'textEdit': [{'range': {'start': {'line': 477, 'character': 5}, 'end': {'line': 477, 'character': 5}}, 'newText': '你好'}], 'server': '文', 'additionalTextEdits': []},...]
可以看到,在 lsp 服务端包装的 TextEdit 对象,在 lsp-bridge 解析后就是一个 json 里的 new_text 入口
lsp-bridge 的 python 进程继续把这份消息传递给 emacs ,emacs 把对象解析成嵌套的 plist,
例如从 lsp-bridge/acm/acm-backend-lsp.el 的 acm-backend-lsp-candidate-expand 函数中,
这份快递的名称叫做 candidate-info, 执行 (plist-get candidate-info :textEdit) 就可以看到以下信息
(:range (:start (:line 477 :character 5) :end (:line 477 :character 5)) :newText 你好)
当你花三分钟认真对比它和上文 python list 以及 LSP 服务里手写的 CompletionList 就会发现 它们的内容基本不会改变,只是在不断传递消息,并且根据不同语言改变消息的封装格式,最后传到 acm 显示在补全窗口中。
替换成可用输入法
使用什么样的输入法不是本文的重点,只要提供与 shurufa 函数一样的接口,任何输入法都可以满足
最终的实现可以参考 metaescape/Wen, 当前我用了 github 上公开的 whatbeg/GodTian_Pinyin,虽然看作者的介绍应该是一个课程项目级别的 demo 输入法,但实际已经可以满足最基本需求了,效果如下
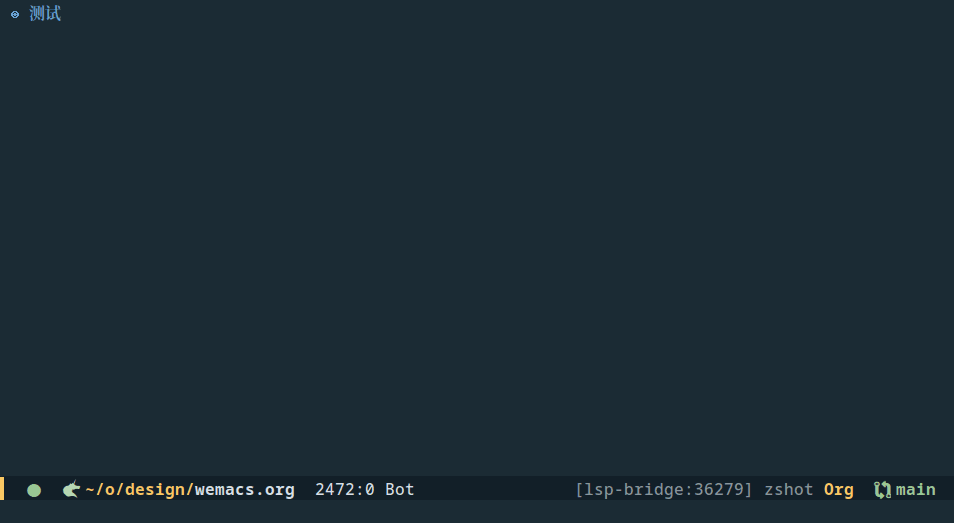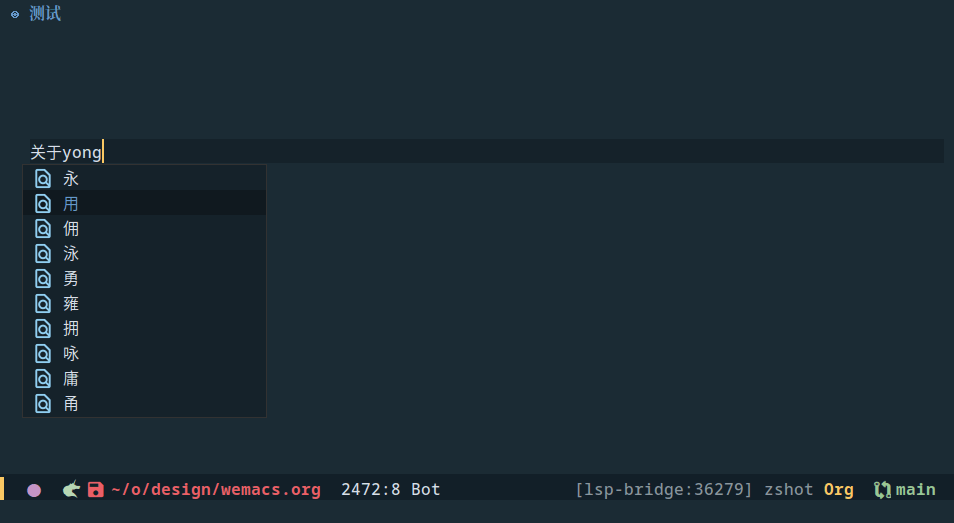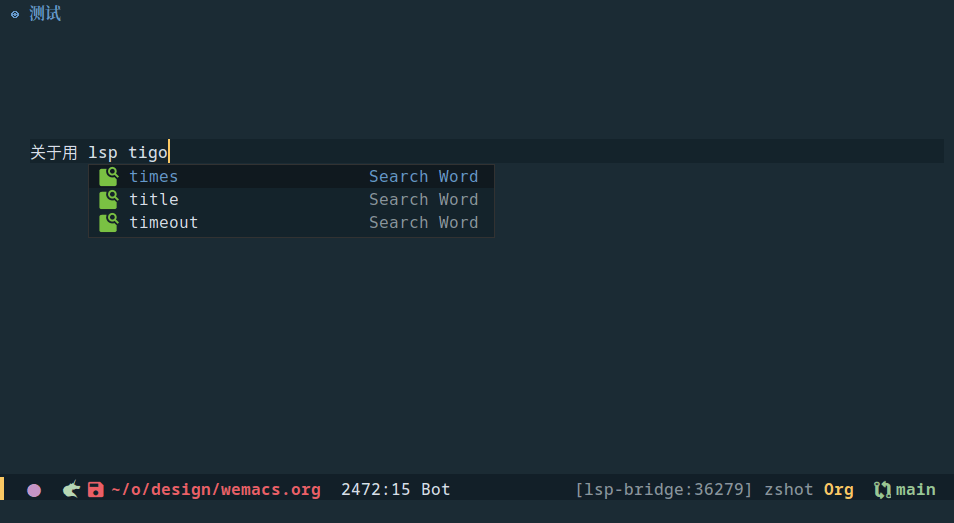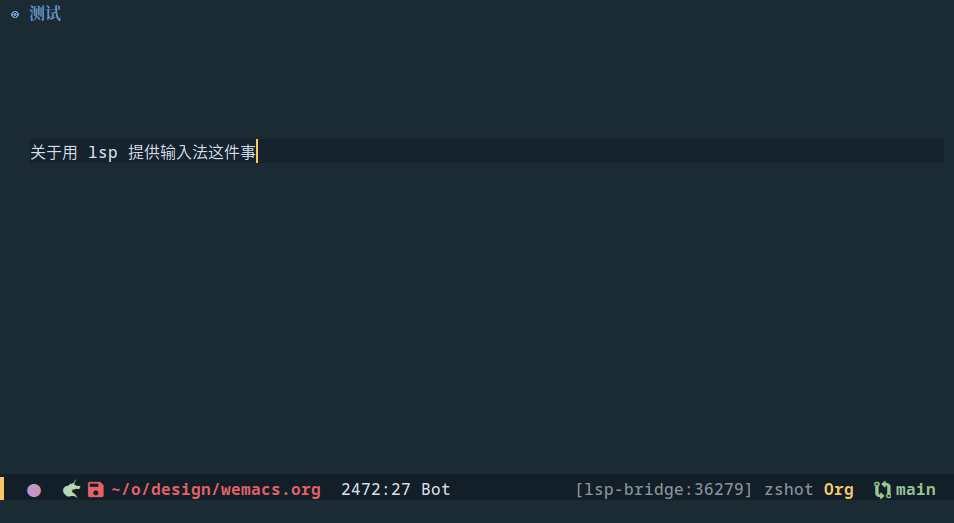
但使用中也发现一些不习惯的地方,最终希望的样子可能是:
- 尽可能地准确,大部分情况下选择第一个就能获得
- 能对长词有比较好的预测效果,充分利用上下文信息
- 需要更好的交互方式,如果只用 tab 和 enter 进行会比较麻烦,可能还是要考虑把空格交互加入进来,例如如果当前第一个候选词是中文,空格代表选词?
后记
对自然语言的分析需求是无止尽的,即使同一种语言,不同的人群都会有不同的"方言",医生有医生的术语,律师有律师的术语,即便是最复杂的模型也不可能满足所有语言理解上的需求,因此关于自然语言 LSP 会成什么样谁也无法预测,但想想还是可以的,本文也只从自己兴趣出发做一些尝试并提供微小经验,或许某个时刻能帮助到同样感兴趣的人,当然包括未来的自己。