深度学习与中文输入法
本文简要梳理最近几年中公开的数篇将深度学习应用在中文(拼音)输入法的研究论文,这个动机来自于以前写的 中文语言服务(language server)的畅想和基础实现 一文中提到的想法。
修改历史
- 添加论文 Generative Input: Towards Next-Generation Input Methods Paradigm
如何定义输入法任务
考虑在一个标准的 PC 键盘上用拼音输入法输入 "xiaoming" 这一串字符串,要能够返回对应的中文词汇,需要考虑以下几个阶段:
- 纠错(Correction): 检查 "xiaoming" 是否输入错误,比如打成了 "xlaoming", 那么可以根据常见错误习惯进行纠正。
- 拼音切分(segment): 把字符串 "xiaoming" 分割成 ["xiao", "ming"]
- P2C (pinyin to character): 将 ["xiao", "ming"] 转换成 "小明" 对于全拼来说,大概有 400 多个不同的拼音词汇,而常用简体汉字有 6000 以上(所有汉字近三万),因此平均每个拼音对应 50 个不同选择(非均匀分布)
- K2C(key stroke to character): 端对端解决方案,连通纠错,分词到拼音转文字一同解决
PIANO 论文中有一张图片对这个过程进行了很好地展示,如下
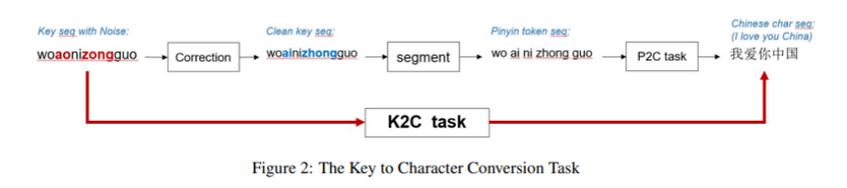
如果用其他输入模式,比如五笔、双拼,或者在手机上用九宫格布局进行输入,任务也是类似的,只是输入的序列不再是拼音,而是对应输入法的某个编码序列。
在实际使用中,只返回一个候选项是不够的,一个拼音序列可能对应多个合理的中文序列,比如 ["xiao", "ming"] 还对应有 "小名", ”晓明“ 等其他词汇,因此对输入法任务更切合实际的一种描述是:
"给定某种 ascii 码组成的序列,输出所有符合该序列的中文序列,且按照用户预期可能性从大到小排序。”
更进一步,还可以把当前光标之前的文本作为上下文一同给输入法,比如 ["他", "的", "xiao", "ming"] 作为输入, 那么输出的候选列表中 "小名" 的概率可能就更高一点(当然也可以把拼音之后的内容也作为上下文,但目前没有看到相关研究)。
在实际应用中, 如果系统输入法要利用输入位置的上下文,需要向各个 APP 申请授权其内容访问的权限,看上去会有隐私保护方面的阻力,但如果只是某些特定编辑器里的输入法,比如代码编辑器里自动补全工具 coplit 或者 tabnine ,获得上下文似乎被认为是比较自然的,集成其中的中文输入法可以看作是带拼音限制或引导的自动补全工具。
对于研究来说,并不用周到地考虑实际使用中的各类问题,因此有些论文只是将输入法看作拼音到中文序列一对一最优解码问题,也就是只考虑候选列表里 top 1 的准确率,有些论文则考虑 top 10 以内的命中率;有些考虑中文上下文,有些则不考虑;有些考虑端对端 K2C 任务,有些则只考虑 P2C 任务。
如何评估输入法的表现
当选定了一个任务之后,需要考虑如何评价针对该任务的模型的好坏,输入法作为人机交互系统,其最终评价来自用户的使用体验,它和输入法前端的设计以及用户使用场景、编辑模式有密切关系。从工程上看,输入法软件可以分为前端和后端,前端是用户输入、选择的交互系统,后端是处理拼音序列到返回中文候选的输入法引擎(IME,input method engine),上一节对问题的定义分类涉及的都只是后端,论文研究基本也都是集中在这部分,因此论文里的测评标准理论上永远无法和真实的完全一致,不过我们至少要理清学术上评价和真实体验评价之间的隔阂有哪些,从而可以选择更加反应真实体验的测评方式。
本节先从简单直接的评价方式开始,然后逐渐将更多的因素纳入以展现其复杂性:
假设想要打出 "小名" 二字, 输入 xiaoming 后返回了 ["小明", “晓明”, "小名"] 三个候选结果, 那么这里第一个选项没有命中,仅针对该例子来说,top1 准确率为 0, 但第三个命中了,因此 top3 及 topk (k>3)准确率都为 1 。这种衡量目标词和候选词是否完全命中的评价方式属于句子粒度的测评指标。
如果该用户将输入法候选列表数量设置为 5, 那么不需要翻页就可以选择到目标词,不过无法通过空格直接将最心仪的 "小名" 上屏, 这体现出了 top1 和其他 topk 的区别,因为 top1 是用户最关心的,人们都希望一次就命中。如果该用户设置的候选列表数量是 2 ,那么要进一步用翻页键之后再用空格才能选到 "小名",这就需要多按一个按键,于是根据按键次数来设计指标看上去是更加贴近用户体验的,在论 (Jia and Zhao, 2013) 中对此类指标有详细的定义。
不过除了目前提到的以选择命中作为结束点的统计方式,还可以把选词后的纠正过程也纳入评价指标,比如某人想输入比较长的句子:“她是一个很好的医师”,但假设候选项第一个是 “她是一个很好的医士”,之后的选项都不提供完整句子,或者第一个字要么都是 "他",要么是部分前缀,如 "她是一个"等(注意这也是一种候选词返回方式,可以不返回整个拼音序列的结果而是返回某个合理的拼音前缀所对应的结果,这样用户要分步多次确认一个长句的多个部分),那么该用户可以先用空格选择该句子,然后删掉最后一个字,再敲入 shi 来选择到"师" 。 这个例子展现的是,有可能我们可以追求更细粒度的测评方式,比如即便第一个候选序列没有完全命中,但可以统计它和目标中文序列的命中的单个字的数量(汉明距离,也是一种字粒度的测评指标)。
如果输入允许是拼音和拼音首字母缩写混合甚至带纠错机制,定义测评又会变得更为复杂,因为这些相当于对原始拼音编码加上了一个按键缩减映射的机制,比如原本 xiaoming 要敲击 8 次键盘,现在由于模型可以支持混合拼音,输入 xiaom 或者 xm 就能返回结果,那么一方面,如 xm 这样的缩写很大概率会导致目标词的排序变大,也就是准确率降低,但按键次数会减少,这就需要在设计测评的时候在按键次数和准确率之间找到平衡。
总之,top1 的完全命中率是最重要的,它的值越高用户就越能无干扰地进行输入,之后的其他指标实际都是一种补救措施,而补救措施和用户的使用行为密切有关(也就是前端设计有关),最常用的是用数字选择非 top1 、翻页,这些操纵的代价可以从 topk 中部分反应(比如 top5 越高表明翻页越少),而汉明距离等细粒度类的测评加入,可以一定程度考虑用户修复错误所需要的代价。
除此之外,返回候选词的效率也需要评估,一般用 ms/char 单位来表示,据说流畅的体验要求每个 token 解码时间应该在 100ms 内,但由于基于 DL 的模型一般都在 GPU 上跑,实际放在 cpu 上的效率测试的比较少,这更多是一个对深度神经网络进行量化、剪枝压缩相关的问题,和输入法核心原理关系不太大,本文不重点关注,但论文里有写的话也会提及。
基于编码器的模型
由于当前 NLP 里的,主流模型都是从 Transformer 衍生出来的,因此总体就是分为基于编码器、基于解码器和基于编码-解码器结果(或者称 seq2seq, 也有时候称为类机器翻译模型)
(Xiao et al., 2022) 论文关心的 P2C 问题,不考虑中文上下文,并且只输出一个目标序列,也就是只拿 top1 候选词进行评测,其中包括包括字粒度准确度,句子粒度准确度和运行时间。
该论文直接把 BERT 模型((Devlin et al., 2019))的输入换成拼音序列,输出则是对应的目标序列,该模型被称为 PERT(Pinyin Encoder Representations from Transformers).
论文提到,由于现成的中文序列转拼音(Text-to-Pinyin, T2P)的工具(如 pypinyin)的准确率高达 99.9%,从无标签的语料库里可以轻松构造出拼音到中文的平行语料库,因此训练 PERT 的规模和无监督的 BERT 训练规模可以是一样的。此外训练时不需要用 Mask Language Model 或者 Next Sentences Prediction 任务,直接预测整个序列,因此本文把输入法看作序列标注问题。
在预测解码的时候在模型输出端用 CRF 层(训练时用 CRF 内存消耗太大,因此不采用),其中的转移矩阵是通过 ngram 统计得到的,也就是说该模型额外和外部的词库结合,这样用 viterbi 解码的时候就可以把外部词库的统计信息加入进来,从而达到融合外部词库的来缓解 OOD 的问题。
PERT 的问题在于,其训练代价比较高,灵活性也比较低,首先用预训练一个 BERT 的代价得到一个纯粹地全拼输入法引擎,如果要换一种输入法比如双拼五笔,还得重新预训练一个(相比之下,原始的 BERT 预训练出来一个通用模型,是为了给下游成百上千个任务进行微调的。)。即便不考虑推理速度,如果某台机器上需要多种不同输入法,得下载好几个预训练模型,因此这个模型可能更适合云输入法?
python 中的 pypinyin 的注意点
由于 PERT 论文提到可以方便构造拼音到文本的平行语料,于是插入本节介绍一下 python 中中文转拼音的库。
首先要意识到的是:中文字是有多音字的,比如 "给" 这个字,在 "交给我” 中读音是 "gei", 在"补给"中拼音是 "ji", 因此许多字读音的确定需要上下文,因此不能把句子拆成单个字去输入个 pypinyin 工具,而是整体输入,或者分词后输入。另外,即便是整词或整局输入,也有可能会出现多个读音的情况。
pypinyin.pinyin 里 heteronym=True 选项可以给出多组拼音,尤其是上下文少的情况:
import pypinyin
print(pypinyin.pinyin("给", heteronym=True))
[['gěi', 'jǐ']]
但默认多音选项是 False, 并且返回的每个字的拼音是一个 list (这是为了和 heteronym=True 的情况返回的形式统一)
print(pypinyin.pinyin("给我"))
[['gěi'], ['wǒ']]
另外 pypinyin.pinyin 的 style=Style.TONE, 中 Stye.TONE 表示会返回音调,一般拼音输入法是不需要的,可以将其设置为 Stye.NORMAL ,pypinyin 提供了 lazy_pinyin 函数,默认返回一个包含每个字拼音字符串的列表,
print(pypinyin.lazy_pinyin("交给我好了,我可以补给一下"))
['jiao', 'gei', 'wo', 'hao', 'le', ',', 'wo', 'ke', 'yi', 'bu', 'ji', 'yi', 'xia']
print(pypinyin.lazy_pinyin("hello, 交给我好了,我可以补给一下"))
['hello, ', 'jiao', 'gei', 'wo', 'hao', 'le', ',', 'wo', 'ke', 'yi', 'bu', 'ji', 'yi', 'xia']
print(pypinyin.lazy_pinyin(["交","给我","好了" ]))
['jiao', 'gei', 'wo', 'hao', 'le']
基于解码器的模型
上节提到,PERT 是纯粹基于 transformer 的编码器的模型,局限在于该模型几乎只能用来做拼音到中文序列的转换任务中,同时无法利用上下文。
之所以会被这么强地限定在拼音这种编码里,是用为 PERT 选择把拼音作为编码器的输入,导致整个模型的参数都和拼音输入强关联, 解决这个问题的方式是,把拼音特征的输入进行"上移", 从模型输入层直接上升到输出层,采用解码器模型就可以达到这个效果,将解码器本身作为一个通用的文本补全工具, 只是在补全采样的过程中,去保证每个时刻采样的 token 符合输入该时刻的拼音限制,这种思路下,从拼音切换成双拼等其他方式的输入法只需要替换一个采样限制表,因此这种做法比 PERT 模型更"环保", 理想情况下下载任何一个开源的中文 GPT 模型,甚至当前的大语言模型,如 GLM , 在采样时加上限制就是可以作为一个输入法引擎了,此外它还可以利用大语言模型的根据上下文进行文本预测的能力。
(Tan et al., 2022) 用字粒度的中文 gpt2 解码器来作为输入法引擎,对于 GPT-2 模型的详细介绍,可以参考另一篇 blog 理解 huggingface transformers 中 GPT2 模型 。 在具体实施过程中,作者们发现目前大多数的 GPT 模型采用的分词算法都不是字粒度的,而是用 BPE 等方式,采样时如果直接进行 token 粒度的限制发现效果很差,可能原因是大部分单字的 embedding 情形没有充分训练到,另外可能是这会使得带限制的 beam search 实现起来变得更困难,比如以下是使用 chatglm 分词器的一个样例:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
sentence = "学习自然语言处理"
tokens = tokenizer.tokenize(sentence)
print(tokens)
['▁', '学习', '自然', '语言', '处理']
假设给定上下文是 "学习自然", 然后输入了 ["yu", "yan","chu", "li"] 四个字,由于对于"语言处理" 最佳分词是两个词,这时候用 yu 去对下一个 token 进行限制的时候就需要考虑更多的词组,比如 "语言","预料","语法", ”雨“等等,此时如果 beam search 的某两个 beam 一个是 "语言", 另一个是 "雨", 那么这两个 beam 在下次采样的时候,限制就不一样了,前者是 ["chu", "li"] 后者是 ["yan", "chu", "li"], 如果要用带拼音限制的损失函数进行训练,可能更麻烦点了。
因此作者找到用字粒度 tokenizer 进行训练的 GPT, 使用公开的 uer/gpt2-chinese-cluecorpussmall 模型作为 baseline 之一,加入拼音限制采样之后,应用 beam size = 16 的 beam search 解码策略, 在 top1 top5 和 top10 准确率上就已经达到 SOTA 了。进一步,作者还用 WuDao 数据集训练了另外一个更强的 GPT2 作为 baseline.
本文另一大目的是对用拼音首字母序列去限制 gpt2 解码的结果,作者发现由于首字母序列,比如 xm 对应太多不同词汇了,因此直接采样准确率会很低,于是引入因拼音特征。
注意上文里的 PERT 模型是只有拼音特征,没有上下文,而 (Tan et al., 2022) 中的到目前介绍的模型是只有上下文(如果是文章开头就不会有上下文),没有拼音特征。
为了加入拼音特征,作者提出了两种模型,核心是把拼音特征作为额外的 embedding, 要么是累加,要么是作为上下文,同时在训练的时候每次只对符合拼音的 token 做 softmax 再计算损失,以保证和采样时分布是一致的。
如下图:
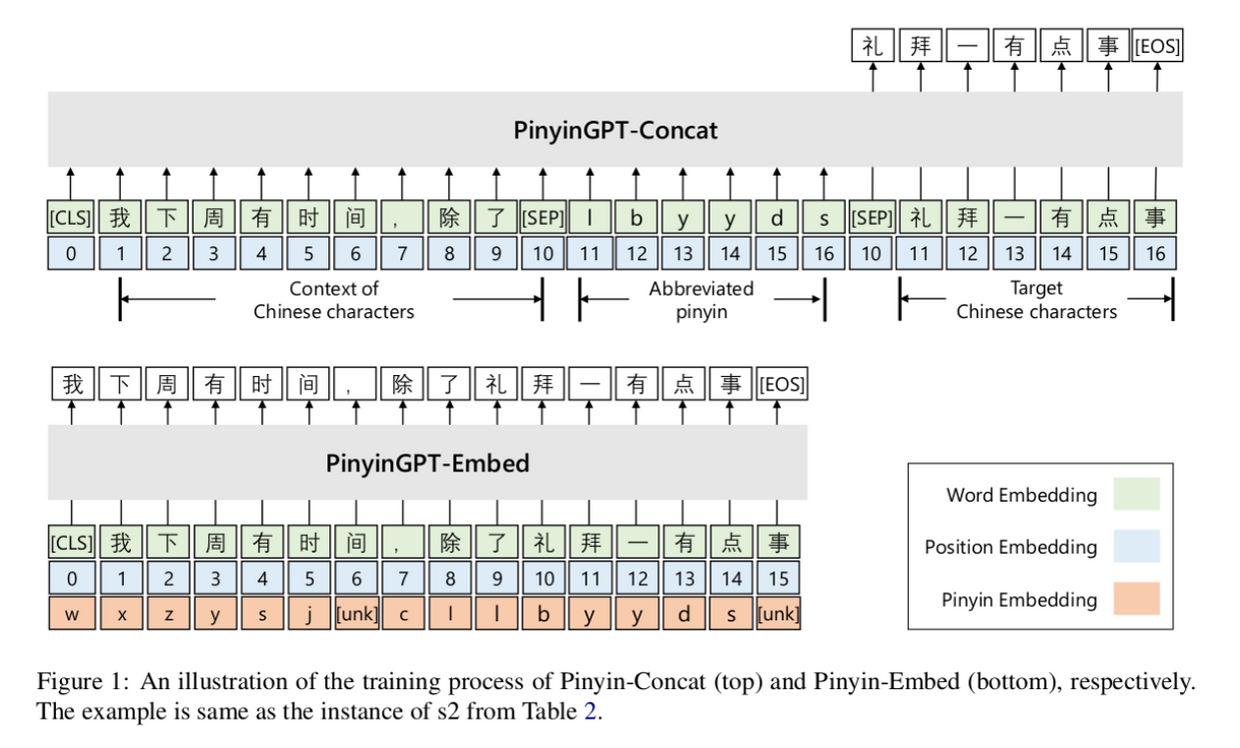
这种方法的局限是什么?个人认为主要还是分词问题,无法与当前的用 BPE 分词的主流大模型比如 chatglm 或中文 llama 等结合(或者换一个角度,中文大模型对于中文分词是否一定要用 BPE, 用字粒度真的会更差吗?),否则在对话 LLM 基础上新增一个 "插件" 就可以把 LLM 作为输入法。假设 llama 等大模型能够很好地小型化,个人 PC 能够轻松支持,或者即便不是个人机器,以某个局域网作为单位(比如放在路由器里)作为支持,那么基于 LLM 的上曾应用既可以有 langchain 生态里的对话、检索等"语义"密集型应用,也可以有中文输入法这种比较贴近语法层面的低层细粒度的应用。
其次就是从整个输入法实现上所面临的的问题,比如能怎么对用户输入的最近的词(或者新的词)进行 cache, cache 后词表怎么融合到 gpt 采样时各个 beam 序列的得分里?如何支持全拼和缩写拼音混合,甚至纠错等与拼音特征密切关联的部分?
最后是解码速度的问题,因为 GPT 是自回归形式,解码只能一个一个生成 token 无法并行,这也引出了用非自回归的解码器的工作。
基于 LLM 的模型
(Ding et al., 2023) 是科大讯飞团队的在 2023 年 11 月份发表在 arxiv 的论文,这篇论文提出的是一个完整的输入交互系统:
其核心是将大语言模型(2.6B 的星火 Spark 模型)融入到输入系统里,任务包括:
按键映射:Full-mode Key-sequence to Characters(FK2C)
- 输入法核心部分,基于全拼
- 但支持从 26 键和一般手机的 9 键布局的键盘序列映射到中文字符串
- 考虑自动纠错,输入缩写的问题
根据不同上下文有不同预测,文中 Table 6 给的部分例子:
wany : 万一 来找我 wany: 玩呀
- 句子补全:Intelligent Association (IntelAssoc)
- 在输入一段话后,给出对下句话的预测(类似 tabnine 或 copilot 对代码的补全)
- 对话助手:Conversational Assistance(ConvAssist):
- 对输入句子的润色,主要针对常用聊天里的对话,比如输入“早上好”可能会提供润色选项“嘿嘿,早上好哦”
三类任务共享一个模型,通过不同的 prompt 来触发不同任务。以下主要介绍 FK2C 模块:
pyseg 阶段把原始按键序列转化成拼音,比如输入序列是 woban, 有可能切分成 wo ban 或者 Wo Ba N ,也有可能是 W O B A N, 每个只是拼音首字母。这个阶段可以类比到 Chain of thought, 即引入推理的中间 过程,只不过此处的推理不是一般 COT 中试图解决的智力型的问题,而是先对原始的输入序列去噪, 尽可能还原成标准全拼,然后根据全拼再输出。
比如原本输入给大模型的问题可能是:你认为拼音 woban 对应的最可能的五个中文词汇是什么?
现在则变成了:请先把用户输入的 woban 拆分最有可能拼音序列,然后给出最有可能的五个中文词汇 (当然可以在这句话之前加入 few shot, 比如 nihaoma 可以拆分成拼音 ni hao ma ,对应的中文词汇有“你好吗”,”你号码“,”你好嘛“ …)
由于拼音预测在预训练模型阶段数据集里是很少的,因此 pyseg 功能依赖于完整的 finetuning (instruction tuning)
- pyseg-Ipnut Alignment: 从 woban 转成 wo ban 是有明确的限制条件的,比如 woban 不会转成 wo bolo, 因此可以在生成拼音的过程中 对 token 进行限制。
- pyseg-output Alignment 根据 wo ban 采样出中文的过程中,只有那些符合的拼音的候选词会被保留
基于编码器-解码器的模型
(Anonymous, 2022) 论文想端对端地来解决输入法问题,本文第一章输入法任务的图就是来自于该模型,其目的是 K2C 任务, 也就是要把纠错、分词、拼音转换用一个模型直接搞定。
因此论文提出的模型直接是以拼音字符串(key stroke)作为输入,其中还可能包括打错的字符(训练时根据键盘的距离来给拼音序列加入部分噪音),比如 "xiaoming" 可能敲击成了 "xiaominf" 因为 f 和 g 比较接近。输入经过一个 encoder 之后输出两种特征:中文序列的长度和拼音字符序列的特征层, 然后将这些特征输入到一个非自回归(NAG)解码器中,解码出最终的中文序列。训练损失就是中文序列长度和中文序列预测两个目标的联合损失:
\[ loss_{total} = \lambda_{1} \star loss_{ce} + \lambda_{2} \star loss_{mse} \]
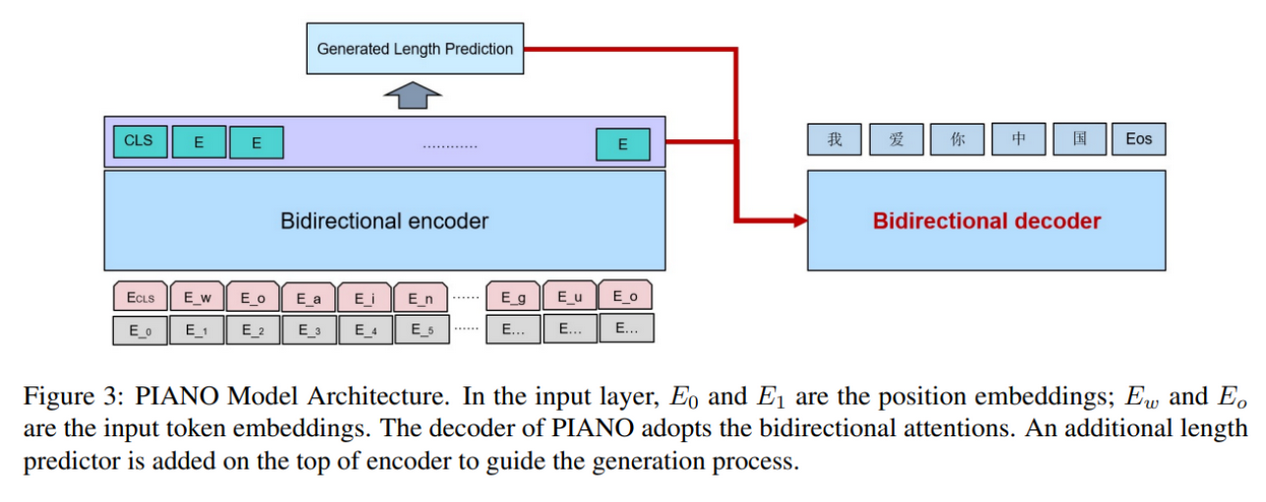
这个做法和 PERT 是比较类似的,主要因为当前考虑的是 K2C 端对端问题而非 P2C,拼音序列无法和目标中文序列一一对应了,于是引入 encoder 取出一个长度特征来解耦。局限和 PERT 也是类似的,就是训练代价很大,训练出的模型只能用来输入拼音,虽然能够对输入序列进行一定的纠错,但由于它是根据标准键盘搜集的按键误击,这也意味着只能适用标准键盘(其他键盘布局如 Colemak 和 Dvorak 等就没法用了,当然这类小众布局几乎都不会在考虑范围内),在手机或者其他编码输入法上都需要分别训练出单独的模型。 当然如果是云服务,可能也没有太大问题。
在 transformer 成为主流之前, (Zhang et al., 2019) 等人用 LSTM 做 seq2seq 模型,这篇文章中重点解决的是如何动态更新词库的问题,由于这个问题在实际使用中是很重要的,因此在此介绍。
这篇文章中输入双向 LSTM 编码器的是拼音序列,通过 attention 链接到解码器,解码器每个时刻返回 output_states 要与所有候选词里的 embedding 做内积进行排序,然后得到候选列表,而词库是动态变化的,也就是如果用户当前输入的某个词汇不在词库里,那么这个词汇会动态加入到字典中,并且通过字粒度和词粒度的 embeding 融合作为这个新词的 embedding. 这种方法的局限之一也是模型只能用作拼音输入法,其次这个系统中包含了在线分词,embedding 融合等“人工”选择痕迹比较强的中间步骤,最后是模型无法利用上下文。
但本文融合动态更新的词库的 online learning 范式值得重新思考,寻找与前文提到的基于 GPT 的模型进行结合的方式。
此外 (Yao et al., 2019) 也用了基于 LSTM 的 seq2seq 模型,并同样维持了一个动态的字典,但其采样用的是 beam search 而不是输出向量与词库中词汇 embedding 的相似度,由于本文是针对日语输入法的,本人不太了解,似乎无法像 (Tan et al., 2022) 里提到的,直接在 beam search 的时候对每个 token 进行限制采样,所以引入了一些词库搜索和更新的策略,通过词库限制来减小 softmax 的计算量,这个问题也许与在基于 BPE 的语言模型上做带拼音限制的 beam search 有所关联。
总结
不考虑测评标准和效率优化,从纯粹模型的角度看,本文梳理了以下几篇论文:
| 文章 | 结构 |
|---|---|
| (Xiao et al., 2022) | Encoder |
| (Tan et al., 2022) | Decoder |
| (Zhang et al., 2019) | Encoder-Decoder(LSTM) |
| (Anonymous, 2022) | Encoder-Decoder(NAG) |
| (Ding et al., 2023) | Decoder(LLM prompt 方式) |
总的来看, Encoder 的好处是可以对特定输入序列进行特征提取,比如带有键盘误击的序列,有望把纠错、分词用同一个模型来处理;Decoder 则是拥有流畅的文本生成能力,二者如何灵活地结合是一个问题。
个人更期待的是能看到基于大模型的输入法(比如 6B 参数以上),尽管这很难直接落地,但至少展示一下 LLM 作为输入法的潜力也好,比如是否能在输入法 benchmark 上把 top1 从 目前 GPT2 的 73 提高到 80 甚至 90 以上? 此外,在 LLM 上做词级别的 online learning 也是个问题。
上一段是 2023 年 10 月的个人看法,一个月后 arxiv 上就有了 (Ding et al., 2023) , 确实在 PD 数据集上把 top1 准确率从 73 提高到了 88, 但这个模型是闭源的,另外,用 prompt 的方式去生成候选词,实时交互的效率可能会是个问题。
其他相关文章
以下两篇是比较早的新闻,其中介绍了基于 LSTM 的输入法引擎,由于是产品介绍,因此只有大体实现思路,并且核心在于部署上