org imagine: 在 org-mode 中想象
修改历史
- 添加插入代码块的功能说明
明月装饰了你的窗,而你装饰了 org mode
org-imagine 用户
以下介绍由 AI 生成:
org-imagine 是一款 emacs org mode 插件,它为 Org mode 用户提供了强大且便捷的图片和代码插入功能。插件的亮点在于其独特的占位符模板系统,用户可以在标准的 shell 命令行中使用诸如 %f %l 样式的占位符来指代 org 文件的对象,将 org 里的内容读取并交给外部命令行程序进行可视化,生成的图片将由 org-imagine 自动链接到文档中。此外,可以用和 org include 的类似语法把某个文件里的源码片段以代码块形式插入到 org 文档。
Org-Imagine 插件的设计理念是使 Org mode 用户在撰写笔记或创建用于导出为 HTML 的博客时能更加高效地工作,使图片和代码片段插入过程无缝集成到您的写作流程中。
一句话概括就是: 用命令行在 org-mode 中插入图片和代码片段。
org-imagine 使用场景展示和命令解释
插入随机封面
给我一张 picsum 里的图片吧

通过以下命令生成:
#+IMAGINE: wget -O %{%o.png} %f
给我一张 [[https://picsum.photos/1366/768/\?random][picsum]] 里的图片吧
#+ATTR_HTML: :width 700 :align center
命令中使用了 %{} , %o.png 和 %f 三种占位符:
%f表示下一行中出现的链接%o表示 org-imagine 根据命令自动计算出的带默认目录的文件名(hash 码形式),形如 ./.org-imagine/abcde, 文件名不带后缀。%{}是告诉 org-imagine, 其中花括号里是最终生成图片的文件名,例如下一个例子中手动指定生成的图片名称,由于 %{} 的存在, org-imagine 才知道./.org-imagine/imagine_picsum.png是正确的图片路径。如果只写%{}则等价于%{%o}, 无法给图片指定后缀。本例中的写法可以明确图片后缀,建议大部分情况下用本例展示的%{%o.png}形式,或像下一个例子里手动指定完整路径的形式, 更加清晰,而不是用%{}。
picsum 是一个图库网站

通过以下命令生成:
#+IMAGINE: wget -O %{./.org-imagine/imagine_picsum.png} %f
[[https://picsum.photos/1366/768/\?random][picsum]] 是一个图库网站
#+ATTR_HTML: :width 700 :align center
你可以执行多次 org-image-view 以获得满意的图片
此外,在 #+IMAGINE 下方可以插入 html 属性规范,它可以设置图片在 org mode 和 html 中的宽度、图片居中等样式,org-imagine 生成图片时会跳过这些控制语句而插入到最后一行 #+ATTR_HTML 的下方。
#+ATTR_HTML: :width 700 :align center
导出 drawio 中绘制的图片
下图展示的是 deeplearning 训练流程
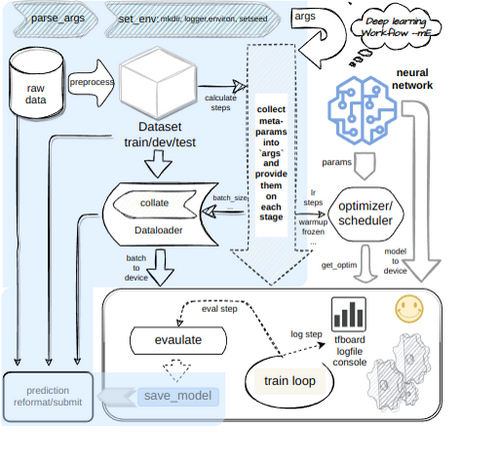
图片生成指令如下
#+IMAGINE: drawio -x %f -o %{.org-imagine/drawio.png} -p 2 --width 500
下图展示的是 [[file:~/org/lib/mE.drawio][deeplearning 训练流程]]
#+ATTR_HTML: :align center
将后缀修改成 svg 可以导出透明背景的矢量图(本例建议在 light 主题下预览):
下图展示的是 deeplearning 训练流程

字体预览

以上图片生成指令为:
#+IMAGINE: pango-view --font="AR PL UKai CN" -qo %{.org-imagine/image1.png} -t "君不见,高堂明镜悲白发" --dpi 400
#+ATTR_HTML: :width 300 :align center
这个例子展现的是不以 org 元素为目标的命令,org-imagine 只是读取 %{} 中的图片路径,执行命令,插入路径并预览。
这类没有 org 对象的命令,语法上要保证 #+IMAGINE: 下一行为空行或者是 #+ATTR_HTML: 属性行,否则默认会找下一行里的链接,给命令添加 -l path 参数(原因在后文中介绍),可能导致错误。
但愿人长久,千里共婵娟
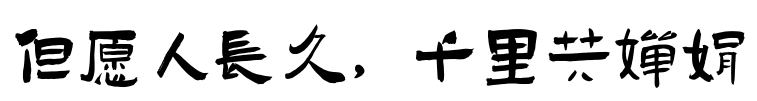
以上图片的生成指令为:
#+IMAGINE: pango-view --font="Slidefu" -qo %{./.org-imagine/image3.png} -t %l --dpi 400
但愿人长久,千里共婵娟
其中的 %l 表示用当前命令下一行的内容进行替换,这是除 org link 外的另一种 org 对象,org-imagine 当前只支持 %f 和 %l, 这已经足够通用,比如 %f 就可以涵盖所有文件格式,如 PPT, PDF, drawio 等等,处理这些文件格式并生成图片的是外部命令,而不是 emacs 本身, org-imagine 只是用少量新增的模板语法提供桥接输入输出的管道,就类似 bash 中的 pipe 管道:
echo hello | less | wc
org-imagine 的模式大致如下:
org-element(%f) | org-imagine(cmd) | [[image.png]](%{})
PPT 页面预览
currently, my keybinding customization schema is :

图片生成指令如下,这里借助了自定义的 pptsnap.py 脚本(放在 org-imagine/view 目录下)。
#+IMAGINE: pptsnap.py -p 2 -s 700
currently, my [[file:/data/resource/ppts/keyboards.pptx][keybinding customization schema]] is :
在本例中,由于 pptsnap.py 一行没有特殊声明, org-imagine 默认读取 #+IMAGINE 下一行中存在的链接
并以 -l path 的参数形式附加给 pptsnap.py 命令,此外,还会自动加上 -d imagine_dir 告诉 org-imagine 图片应该生成在哪个目录。这意味着图片名称是 pptsnap.py 自动生成的,它通过标准输出把文件名返回给 org-imagine
因此,可以根据自己的需求,参考 org-imagine/view 目录下的其他脚本,在其中添加自己的可视化程序,但要遵循的规则包括:
- 脚本支持
-l和-d参数,其中 -l 后是文件的完整 link, 形如[[file:ppts/keyboards.pptx]],-d 是指定图片生成目录。用户脚本中自己取解析[[file:ppts/keyboards.pptx]]连接,比如提取出纯路径部分ppts/keyboards.pptx, 然后取对这个文件生成图片 - 脚本最后应该打印出图片名称,比如 print(f"{arg.imagine_dir}/imagine.png")。 python 用 print, bash 用 echo
pdf 预览图
[BROKEN LINK: pdf:/data/resource/readings/manual/2020-Causal_Inference-Hernan-Robins.pdf::1]

生成命令如下:
#+IMAGINE: pdfsnap.py -s 70
[[pdf:/data/resource/readings/manual/2020-Causal_Inference-Hernan-Robins.pdf::1]]
真正被执行命令是:
~/.emacs.d/site-lisp/org-imagine/view/pdfsnap.py -s 70 -l "/data/resource/readings/manual/2020-Causal_Inference-Hernan-Robins.pdf" -d ./.org-imagine
org-imagine 不提供对链接中页码的解析,因此即便以下 pdf 连接中有 xxx.pdf::1 样式的页码,但用户还是需要在具体执行的命令中声明页码,如下的 -f 1 表示第 1 页:
以下是用 pdftoppm 系统命令直接读取 pdf
#+IMAGINE: pdftoppm -png -f 1 -scale-to 100 -singlefile %f %{%o}
[[pdf:/data/resource/readings/manual/2020-Causal_Inference-Hernan-Robins.pdf::1]]
[BROKEN LINK: pdf:/data/resource/readings/manual/2020-Causal_Inference-Hernan-Robins.pdf::1]

%f会被下一行内的文件路径替换,%{}会被自动生成的快照文件名替换,这种方式与 org-capture 里的 Template expansion (The Org Manual) 类似%f还可以将[[id:abcde]]形式的链接转换成该 id 对应的 org 文件路径
org 文件可视化
this is my 2021 journal streak:
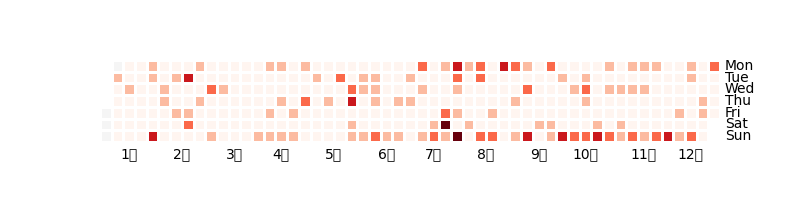
上图生成指令如下,借助了 org-imagine/view/timemap.py 脚本
#+IMAGINE: timemap.py
this is my [[file:~/org/self/journal/j2021.org][2021 journal]] streak:
这里没有任何参数,因为解析后会默认加入以下参数
-l [[file:~/org/self/journal/j2021.org][2021 journal]] -d ./org-imagine
插入 stable diffusion webui 生成的图片
假设 stable diffusion webui 启动的 ip 和端口是 192.168.168.2:7861 ,那么图片生成指令如下:
#+IMAGINE: sdtext2img.py -e 192.168.168.2:7861 -o %{%o.png} -j %f
这是一张水墨的[[file:/tmp/shuimo.json][独角兽]]\\
这是一张水墨的独角兽

本例实际上在做的是把 json 文件地址作为参数传给 org-imagine/eiw/sdtext2img.py ,
因此也可以把 json 文件写在 org src block 里,然后 tangle 到对应路径后再执行 org-imagine-view (也可以把 tangle 和 org-imagine-view 包装成一个单独的命令),以下 block 的 header 里有 :tangle /tmp/shuimo.json 选项
{
"sd_model_checkpoint": "moonmix_fantasy",
"seed": -1,
"width": 612,
"height": 200,
"prompt": "<lora:MoXinV1:0.4>, shukezouma, negative space,shuimobysim ,a (unicorn:1) beside a river, traditional chinese ink painting",
"negative_prompt": "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,",
"cfg_scale": 3,
"steps": 20,
"sampler_index": "DPM++ 2M Karras",
"override_settings": {
"CLIP_stop_at_last_layers": 2
}
}
手动执行的命令如下:
python view/sdtext2img.py -e 192.168.168.2:7861 -o /tmp/sd.png -j /tmp/shuimo.json
插入代码块
org-imagine 不单可以通过命令插入图片,还可以从源码文件中根据语言结构提取代码块,这适合于学习某个项目源码或给自己的项目的关键的函数、类进行注解的场景,可以用以下语法:
#+IMAGINE: "~/codes/tpdsl-python/parsing/lexer.py::class Lexer"
class Lexer:
'''
A Abstract Lexert class
'''
# string with < > is the token and the string without < > is the token type
type_map = {"<NA>": "NA", "<EOF>": "EOF"}
def __init__(self, input: str):
self.input = input
# set all key, value in type_map to class attribute
for token, token_type in self.type_map.items():
setattr(self, token_type, token)
setattr(self, f"{token_type}_TYPE", token_type)
self.p = 0 # Index into input of current character
self.c = self.input[self.p] if self.input else self.EOF # Prime lookahead
def consume(self):
"""Move one character; detect 'end of file'."""
self.p += 1
if self.p >= len(self.input):
self.c = self.EOF
else:
self.c = self.input[self.p]
def match(self, x):
"""Ensure x is next character on the input stream."""
if self.c == x:
self.consume()
else:
raise ValueError(f"Expecting {x}; found {self.c}")
def get_type(self, token_type):
"""Abstract method to get the token name."""
raise NotImplementedError
然后执行 org-imagine-view, 就会把 ~/codes/tpdsl-python/parsing/lexer.py 文件里的 Lexer 类的所有代码用 python src block 的形式插入到 IMAGINE 中。这样就可以在 org 中直接写对该类的介绍或个人理解了。而如果该类没有额外的依赖,还可以直接在 babel 中执行。
通过添加 :only-contents 选项(和 #+INCLUDE 的一样)后执行 org-imagine-view, 提取的代码会删除 docstrings, 保留代码和注释(仅针对 python 代码)
#+IMAGINE: "~/codes/tpdsl-python/parsing/lexer.py::class Lexer" :only-contents
或者
#+IMAGINE: "~/codes/tpdsl-python/parsing/lexer.py::class Lexer" :only-contents t
都会把以下 docstrings 删除掉
''' A Abstract Lexert class '''
此外通过 C-C ' 可以跳转到文件的相应位置并支持一般 org link 中 搜索选项 (The Org Manual) 的格式
目前只支持 python (根据缩进抽取对象)和 emacs-lisp (读取 s-expression)
与其他相似功能的包的对比:
org mode 自带的
#+INCLUDE:语法: org-imagine 导入代码中,代码路径的格式和 org 的 #+INCLUDE 是类似的,并且通过C-C '跳转到源码也是参考了 INCLUDE 的机制。#+INCLUDE: "./paper.org::#theory" :only-contents t
不同点在于:
- INCLUDE 只是在导出的时候把内容插入,这就使得代码无法在 org 里通过 org-babel 执行。
- IMAGINE 可以给定函数名和类而提取出语义对象的内容(当然为了简单化,还是用正则方式提取,并没有使用 parser),而 INCLUDE 只支持 org 的 subtree 这种结构提取,或者用
:line 1-20行号范围的格式,这需要人为地找出代码开始和结束的行号, 并且一旦修改源码,导出的代码块很可能就变了,比较麻烦。 IMAGINE 支持 Link abbreivate, 可以用以下方式引用
#+IMAGINE: "proj:class ABC"
记得在 org 中添加
#+LINK: proj ~/codes/proj/core.py::%s
- org-transclusion 可以把其他文件的某一部分添加到当前 org 中,我没有用过这个包,因此以下都是看了其 readme 和一些功能介绍后的推测:
- transclusion 插入的只是一个链接,而不是代码,这导致:
- 可能无法用 babel 执行
- 可能无法方便导出成 html 或其他文件(其 github 里有一些没有解决的 issue: Text read-only while exporting to other formats · Issue #86 · nobiot/org-transclusion )
- transclusion 文本里的内容和源文件内容是同步的,可能无法做一些过滤操作,比如删掉注释或只保留 docstring, 或者手动做一些修改等。
- 和 #+INCLUDE 类似, transclusion 不支持结构性地代码块导入,只能指定行号范围,这是促使我自己写代码导出功能的主要原因。
- transclusion 能插入各种片段,但 imagine 只插入代码块。
- transclusion 插入的只是一个链接,而不是代码,这导致:
代码执行过程
本节记录了执行 org-imagine-view 后的代码的执行流程
总体
整个插件执行逻辑是线性的,主要分成三步:
- 读取和解析
#imagine:之后的 shell 命令(用正则匹配方式对模板展开) - (异步)执行 shell 命令生成图片
- 在合适位置(同上是内容的下一行)插入图片链接
读取和解析命令
由 org-imagine–read-and-parse-cmd 函数处理命令的解析,这是 org-imagine 的核心, 以 #+IMAGINE: showmecode -t -f %f -o %{} 为例:
- 找到
#+IMAGINE标识后调用 org-imagine–get-cmd, 获取#+IMAGINE:之后的内容作为待解析的命令行 调用 org-imagine–expand-viewer, 找到命令行中第一个英文单词作为可执行命令,检查其是否在 org-imagine-view-dir 目录下, 如果在,则拼接成绝对路径后返回,如果不在则看作系统命令返回。
对于以上例子,如果 showmecode 是在默认 view 目录下,那么此时待解析的命令 cmd 替换成
~/.emacs.d/site-lisp/org-imagine/view/showmecode -t -f %f -o %{%o.png}调用 org-imagine–fill-cmd-input 填充命令里的
%f等输入源占位符,同时进一步确定语义信息 该函数输出三个对象,第一个是对 input 占位符填充过后的完整命令,第二是填充的内容 用于自动生成输出的图片名,最后是命令的类型具体含义见下一节
input placeholder expansion
input placeholder 指的是 %f 和 %l
仍然以 #+IMAGINE: showmecode -t -f %f -o %{} 为例,其中的 %f 将被替换为 #+IMAGINE 下一行里出现的 [[file:xx]] 或 [[id:xx]] 或 [[pdf:xx]] 或 [[https:xx]] 中的目标路径,对于 [[file:xx]] 会抽取出 xx ,而 [[id:yy]] 则需要把 yy 转成路径。这与 org-capture 中的 template-expansion 思想是类似的。
假设 showmecode 下一行中第一个链接是 [[file:~/a.py]] 那么当前 cmd 替换的结果是:
~/.emacs.d/site-lisp/org-imagine/view/showmecode -t -f ~/a.py -o %{%o.png}
微妙的部分在于确定命令的类型,由 org-imagine–get-input-content 承载,出于精简指令的动机,命令分为两类:
snap 快捷命令
在
org-imagine/view目录里维护了一些灵活的可视化脚本,比如pdfsnap.py和pptsnap.py,它的--link或-l参数可以解析[[file:path::page]]整个链接的内容(%f只会提取其中的 path 部分),这些 python 脚本的内部再对 link 做更精细的解析,例如把页数 page 也取出来。此外它们还包括 -d 选项,用于指定图片生成的目录文件夹位置。这种设计使得此类命令可以不在
#+imagine行里添加%f或者%o占位符,比如以下语法就可以把 mynote.ppt 的第 10 页转成 dpi=500 的图片#+IMAGINE: pptsnap.py -p 10 -s 500 [[~/mynote.ppt]]
它实际会自动转换成以下命令并执行
pptsnap.py -p 10 -s 500 -l=[[~/mynote.ppt]] -d ./org-imagine/
- noraml 命令:除去 snap 以外的命令,也就是命令行中必须声明
%f这样的占位符的命令,大部分系统命令行都属于这类。
命令类别的判断逻辑是:
- 先做 input placeholder expansion, 如果 expansion 成功(找到了占位符并替换了内容),那么肯定是 normal 命令,否则就是 snap.
- 对于 snap 命令,在 input expansion 的基础上加入 -l 和 -d 选项。
output placeholder expansion
output placeholder 指的是 %{} 和 %o
- org-imagine–fill-cmd-input 返回了展开的命令行以及要可视化的对象后。 org-imagine–get-output-path 根据这两个参数自动计算出 hash 值作为输出图片的文件名(不包括后缀)
- 如果 input 对象是一个合法路径,那么读取文件名称和修改时间,否则这两个分别用 N 和 T 表示
- 对整个命令做 hash, 最后返回 filename-modified-hash 形式的图片名
接着 org-imagine–fill-cmd-output 获取命令和 hash 图片名,把图片名替换命令中被
%{}包裹的部分如果是
%o则填充自动生成的图片名,如果是用户指定了路径,如%{abc.png}, 则获得abc.png,%{}使得 org-imagine 能够读取用户指定生成图片路径或由 org-imagine 自动计算出的 hash 图片名。这部分具体由 org-imagine–get-input-content 负责
snap 命令的自动处理:
- 如果命令中不包括输出
%o或者%{}占位符,说明这是一个 snap 默认命令,这类命令默认加上 -d org-imagine-cache-dir 选项到命令末尾
异步执行命令
用 start-process-shell-command 对最终解析出的命令行进行异步调用,这个函数是对 start-process 的封装, 而 start-process 又对 make-process 封装。
为了获得进程的标准输出,可以用 process-filter, 这类函数的第二个参数默认就是进程标准输出, 对进程设置 set-process-filter 后,如果命令没有标准输出时,不会调用 filter ,因此如果是执行系统命令(例如 wget ,默认没有返回值),就无法正常插入。
(let
(proc
(start-process-shell-command
"org-imagine-view"
nil
final-cmd)))
(set-process-filter
proc
(lambda (proc cmd-out-path)
(when (not img-path)
(org-imagine--insert-image marker cmd-out-path))))
(set-process-sentinel
proc
(lambda (proc event)
(when (and (equal event "finished\n") img-path)
(org-imagine--insert-image marker img-path))))
为此,继续加入 set-process-sentinel, 哨兵函数会在进程状态变化时触发,因此在 finished 状态后,检查 output expansion 之后的图片路径是否存在:
- 如果存在,说明要插入的图片来自于 imagine 自动生成,因此直接把该路径插入即可
- 如果不存在,那么这就是 snap 命令,图片路径来自 cmd 执行结果,这时候 process-filter 自然会处理。
插入图片链接并预览
org-imagine-is-overwrite 变量如果不是 nil, 那么插入的图片链接不会覆盖当前链接,否则先删除图片链接再插入。
函数 org-imagine–insert-below 负责插入逻辑,执行前光标是停留在 #+IMAGINE 注释的位置上,因此
- 先往下移动两行,当前要么是
#+ATTR,要么是已经插入的图片链接行,要么是空行(必须预留空行) - 检查是否在
#+ATTR上,如果在,则一直向下移动,直到不是#=ATTR行 - 此时就剩下空行和链接两个选项:
- 如果不是空行且 org-imagine-is-overwrite 非 nil, 则先删除当前行(删除后使得当前行处于空行)
- 由于当前就是空行,因此直接插入图片链接并且调用 preview
org-imagine 不插入 #+ATTR 的原因:用 yasnippet 类内容展开插件添加 #+imagine 命令行和 #+ATTR 属性行是最灵活的,没必要 org-imagine 来处理。
具体来说,自动加入 #+ATTR 可能并不适合 org-imagine, 原因在于,很多时候会重复执行 org-imagine 以生成符合要求的图片,因此只要手动插入一次命令行,之后大部分时间都是在
"执行 imagine-view 命令->查看图片效果->调整命令->执行 imagine 命令" 的循环过程中,如果每次执行 imagine-view 都插入 #+ATTR 会导致重复。
加入 #+ATTR 的想法来自 org-download, #+ATTR 对于 org-download 是合适的,因为每次插入图片是鼠标操作,之后很少重复去插入图片,即便当前插入的不满意,重复插入一遍,也会把之前的全部删除,因此有必要把 #+ATTR 再一起插入。
开发和使用经验
- 开发中花了不少时间去实现自动生成 hash 码作为图片名称的功能,也就是对占位符
%o的实现,但实际使用中发现大部分时候自己都是指定图片名称如%{./img/img_out.svg},很少用到%o. - debug 方式: 每次执行 org-image-view 时会在
*Messages*buffer 打印出真正执行的命令,如果插入图片失败,可以先复制这个命令到终端执行,检查命令是否有误。 用 yasnippet 或其他代码片段展开工具来快速插入命令模版,比如:
- imagine :: #+IMAGINE: ${0:pdfsnap.py} -s 300 - wget :: #+IMAGINE: wget -O %{%o.png} %f - attr :: #+ATTR_HTML: :width ${0:800} :align center然而使用中发现真正调用模板展开的时候并不多,基本都是先搜索到以前插入过的某个命令,复制到当前需要插入图片的位置后修改成希望的命令。